这里放些字符串相关,总之也就是从头再学字符串了。
border:一个字符串的真前缀,并且它和该字符串的一个真后缀相等。
周期:对于字符串 s s s 0 < p ≤ ∣ s ∣ 0 < p \le |s| 0 < p ≤ ∣ s ∣ ∀ i , s [ i ] = s [ i + p ] \forall i, s[i]=s[i+p] ∀ i , s [ i ] = s [ i + p ] p p p s s s
l c p ( a , b ) lcp(a, b) l c p ( a , b ) a a a b b b
l c s ( a , b ) lcs(a, b) l c s ( a , b ) a a a b b b
比较简单基础的算法,但是用处够多。
具体实现不说了,应该都会。主要可以用来在忘了 SA 板子怎么写后去 O ( log n ) O(\log n) O ( log n ) O ( 1 ) O(1) O ( 1 )
KMP 是用来求解一个字符串的所有前缀的最长 border 的算法。具体算法流程如下:
我们定义 n e x t [ i ] next[i] n e x t [ i ] i i i n e x t [ 1 ] = 0 next[1]=0 n e x t [ 1 ] = 0 n e x t [ i ] next[i] n e x t [ i ] n e x t next n e x t
我们可以结合下面的图来理解:
图中我们发现 i − 1 i-1 i − 1 i i i i i i
代码如下:
1 2 3 4 5 6 7 ne[1 ] = 0 ; for (int i = 2 , j = 0 ; i <= m; i ++ ){ while (j && t[i] != t[j + 1 ]) j = ne[j]; if (t[i] == t[j + 1 ]) j ++; ne[i] = j; }
由于每轮循环 j j j + 1 +1 + 1 j j j m m m O ( ∣ s ∣ ) O(|s|) O ( ∣ s ∣ )
例题后面有。
exKMP 和 KMP 相似,但是它是用来求字符串的前缀和该字符串的某个后缀的最长匹配长度。可以想象成这个字符串往后平移,平移到某个位置后从这个字符串开头进行匹配。
在 exKMP 中,我们有一个数组 z i z_i z i i i i [ i , ∣ s ∣ ] [i, |s|] [ i , ∣ s ∣ ] z i z_i z i
首先,显然的是 z 1 = ∣ s ∣ z_1=|s| z 1 = ∣ s ∣ ∣ s ∣ |s| ∣ s ∣ z z z
代码如下:
1 2 3 4 5 6 7 8 9 10 inline void getz (char *s, int n) z[1 ] = n; for (int i = 2 , l = 0 , r = 0 ; i <= n; i ++ ) { if (i <= r) z[i] = min (z[i - l + 1 ], r - i + 1 ); while (i + z[i] <= n && s[i + z[i]] == s[z[i] + 1 ]) z[i] ++; if (i + z[i] - 1 > r) r = i + z[i] - 1 , l = i; } }
由于每次 while 循环至少使得 r r r r ≤ n r \le n r ≤ n n n n O ( ∣ s ∣ ) O(|s|) O ( ∣ s ∣ )
manacher 算法是用来快速求解字符串中回文串的算法。具体算法流程如下:
我们先对字符串进行预处理,在左右两边加入哨兵,再在每两个字符之间加入一个相同的且在原串中不存在的字符,来使得偶回文串变为奇回文串。我们再设 f i f_i f i i i i
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 inline void manacher (char *t) n = strlen (t + 1 ); s[0 ] = '#' , s[1 ] = '$' ; for (int i = 1 ; i <= n; i ++ ) s[i << 1 ] = t[i], s[i << 1 | 1 ] = '$' ; n = n << 1 | 1 ; s[++ n] = ')' ; for (int i = 1 , mid = 0 , r = 0 ; i <= n; i ++ ) { f[i] = 1 ; if (i <= r) f[i] = min (f[2 * mid - i], r - i + 1 ); while (s[i - f[i]] == s[i + f[i]]) f[i] ++; if (i + f[i] - 1 > r) r = i + f[i] - 1 , mid = i; } }
时间复杂度分析同 exKMP。
没啥可说的,就只是单纯的字典树。
对于异或问题基本上要么想拆位,要么线性基,要么应该就是 01 Trie 了。
注意 01 Trie 的空间复杂度为 O ( n log n ) O(n\log n) O ( n log n )
可持久化 Trie 和主席树差不多,基本上都是维护前缀的信息用的,只不过可持久化 Trie 一般是维护异或信息的。
AC 自动机和 KMP 类似,都是求解字符串匹配的问题,但是 AC 自动机可以支持多模式串对一个文本串进行匹配,时间复杂度同样也是线性。
AC 自动机一开始可以看作一颗 trie 树。在 AC 自动机中,我们类似 KMP,我们维护一个 f a i l fail f a i l f a i l fail f a i l
对于求 f a i l fail f a i l f a i l fail f a i l
在 AC 自动机中,我们可以对 f a i l fail f a i l 26 26 2 6 t r [ p ] [ u ] tr[p][u] t r [ p ] [ u ] p p p u u u f a i l fail f a i l f a i l fail f a i l
代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 inline void insert (char *s, int ident) int p = 0 ; for (int i = 1 ; s[i]; i ++ ) { int t = s[i] - 'a' ; if (!tr[p][t]) tr[p][t] = ++ idx; p = tr[p][t]; } if (!id[p]) id[p] = ident; mp[ident] = id[p]; } inline void build () queue<int > q; for (int i = 0 ; i < 26 ; i ++ ) if (tr[0 ][i]) q.push (tr[0 ][i]); while (q.size ()) { int t = q.front (); q.pop (); for (int i = 0 ; i < 26 ; i ++ ) { int u = tr[t][i]; if (!u) tr[t][i] = tr[fail[t]][i]; else { fail[u] = tr[fail[t]][i]; din[fail[u]] ++; q.push (u); } } } } void query (char *s) for (int i = 1 , j = 0 ; s[i]; i ++ ) { int t = s[i] - 'a' ; j = tr[j][t]; val[j] ++; } }
代码来源于AC 自动机(二次加强版) 。我们可以注意到,在查询出现次数时,我们为了优化复杂度,利用了树上差分的思想,某个点如果出现过,那么它 f a i l fail f a i l f a i l fail f a i l f a i l fail f a i l
PAM 中有两棵树,分别对应着字符串中的奇回文串和偶回文串。而 PAM 中的 f a i l fail f a i l f a i l x fail_x f a i l x x x x f a i l fail f a i l
当我们要新加入一个字符时,它可能会和原字符串中的末尾形成一个回文串。由于是回文串,因此两边同时扣掉一个字符依旧是回文串。我们发现这个回文串也就是一个回文后缀。我们直接在这个回文后缀所对应的节点后挂上这个节点即可。这个过程就可以用 f a i l fail f a i l
关键结论:s s s log ∣ s ∣ \log |s| log ∣ s ∣
建树代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 inline int getfail (int x, int i) while (i - len[x] < 1 || s[i - len[x] - 1 ] != s[i]) x = fail[x]; return x; } inline void build (int n) len[1 ] = -1 , fail[0 ] = 1 ; idx = 1 ; for (int i = 1 ; i <= n; i ++ ) { pos = getfail (cur, i); int u = s[i] - 'a' ; if (!tr[pos][u]) { fail[++ idx] = tr[getfail (fail[pos], i)][u]; tr[pos][u] = idx; len[idx] = len[pos] + 2 ; } cur = tr[pos][u]; } }
SA 是一个把所有后缀都放到一个数组,支持动态查询一个后缀的排名的结构。在其中有两个重要数组:s a i sa_i s a i r k i rk_i r k i s a i sa_i s a i i i i r k i rk_i r k i i i i
有一个很简单的构建方法就是把所有后缀都搂出来然后 sort 一下。但是字符串比较是 O ( n ) O(n) O ( n ) O ( n 2 log n ) O(n^2\log n) O ( n 2 log n ) r k i rk_i r k i
每次只会对两个关键字进行比较。我们可以简单粗暴用 sort,时间复杂度 O ( n log 2 n ) O(n\log^2 n) O ( n log 2 n ) log \log log O ( n log n ) O(n\log n) O ( n log n )
构建代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 m = 127 ; for (int i = 1 ; i <= n; i ++ ) rk[i] = s[i];for (int i = 1 ; i <= n; i ++ ) cnt[rk[i]] ++;for (int i = 1 ; i <= m; i ++ ) cnt[i] += cnt[i - 1 ];for (int i = n; i >= 1 ; i -- ) sa[cnt[rk[i]] -- ] = i;memcpy (oldrk + 1 , rk + 1 , n * sizeof (int ));for (p = 0 , i = 1 ; i <= n; i ++ ){ if (oldrk[sa[i]] == oldrk[sa[i - 1 ]]) rk[sa[i]] = p; else rk[sa[i]] = ++ p; } for (w = 1 ; w < n; w <<= 1 ){ m = p; for (p = 0 , i = n; i > n - w; i -- ) id[++ p] = i; for (i = 1 ; i <= n; i ++ ) if (sa[i] > w) id[++ p] = sa[i] - w; memset (cnt, 0 , sizeof cnt); for (int i = 1 ; i <= n; i ++ ) ++ cnt[rk[id[i]]]; for (int i = 1 ; i <= m; i ++ ) cnt[i] += cnt[i - 1 ]; for (int i = n; i >= 1 ; i -- ) sa[cnt[rk[id[i]]] -- ] = id[i]; memcpy (oldrk + 1 , rk + 1 , n * sizeof (int )); for (p = 0 , i = 1 ; i <= n; i ++ ) { if (oldrk[sa[i]] == oldrk[sa[i - 1 ]] && oldrk[sa[i] + w] == oldrk[sa[i - 1 ] + w]) rk[sa[i]] = p; else rk[sa[i]] = ++ p; } }
我们还可以求出一个数组 h e i g h t i height_i h e i g h t i l c p ( s a i , s a i − 1 ) lcp(sa_i, sa_{i-1}) l c p ( s a i , s a i − 1 ) h e i g h t [ r k [ i ] ] ≥ h e i g h t [ r k [ i − 1 ] ] − 1 height[rk[i]] \ge height[rk[i-1]]-1 h e i g h t [ r k [ i ] ] ≥ h e i g h t [ r k [ i − 1 ] ] − 1
对于 h e i g h t height h e i g h t l c p ( s a [ i ] , s a [ j ] ) = min { h e i g h t [ i + 1 ] ⋯ h e i g h t j } lcp(sa[i], sa[j])=\min \{height[i + 1]\cdots height_{j} \} l c p ( s a [ i ] , s a [ j ] ) = min { h e i g h t [ i + 1 ] ⋯ h e i g h t j } l c p lcp l c p
SAM 是一张 DAG,存储了一个字符串的所有子串。我们必然不能把后缀一个一个插入 trie 树里面当 SAM 用,但是我们可以利用 parent tree 来构建。
parent tree 是利用了字符串的子串的 e n d p o s endpos e n d p o s
SAM 的具体构建这里不细说了,但是 SAM 中的后缀链接(即 l i n k [ x ] link[x] l i n k [ x ]
(这里是真的不想写了要细写估计得再开一篇博客写)
注意 :SAM 的节点数最多为 2 n − 1 2n-1 2 n − 1 3 n − 4 3n-4 3 n − 4
构建代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 inline void extend (char *s) int n = strlen (s + 1 ); for (int i = 1 ; i <= n; i ++ ) { int p = last, cur = ++ idx, c = s[i] - 'a' ; f[cur] = siz[cur] = 1 ; len[cur] = len[p] + 1 ; while (p != -1 && !tr[p][c]) { tr[p][c] = cur; p = link[p]; } if (p == -1 ) link[cur] = 0 ; else { int q = tr[p][c]; if (len[q] == len[p] + 1 ) link[cur] = q; else { int copy = ++ idx; len[copy] = len[p] + 1 ; link[copy] = link[q]; for (int i = 0 ; i < 26 ; i ++ ) tr[copy][i] = tr[q][i]; while (p != -1 && tr[p][c] == q) { tr[p][c] = copy; p = link[p]; } link[cur] = link[q] = copy; } } last = cur; } for (int i = 1 ; i <= idx; i ++ ) G[link[i]].emplace_back (i); }
点击查看
我不会,以后再学习
Matching
对于整数序列 ( a 1 , a 2 , ⋯ , a n ) (a_1,a_2,\cdots,a_n) ( a 1 , a 2 , ⋯ , a n ) 1 ∼ n 1\sim n 1 ∼ n ( p 1 , p 2 , ⋯ , p n ) (p_1,p_2,\cdots,p_n) ( p 1 , p 2 , ⋯ , p n ) ( a 1 , a 2 , ⋯ , a n ) (a_1,a_2,\cdots,a_n) ( a 1 , a 2 , ⋯ , a n ) ( p 1 , p 2 , ⋯ , p n ) (p_1,p_2,\cdots,p_n) ( p 1 , p 2 , ⋯ , p n )
{ a } \{a\} { a }
将 ( a 1 , a 2 , ⋯ , a n ) (a_1,a_2,\cdots,a_n) ( a 1 , a 2 , ⋯ , a n ) ( a p 1 , a p 2 , ⋯ , a p n ) (a_{p_1},a_{p_2},\cdots,a_{p_n}) ( a p 1 , a p 2 , ⋯ , a p n )
现在给出 1 ∼ n 1\sim n 1 ∼ n { p } \{p\} { p } h 1 , h 2 , ⋯ , h m h_1,h_2,\cdots,h_m h 1 , h 2 , ⋯ , h m { h } \{h\} { h } { p } \{p\} { p }
数据范围:n , m ≤ 1000000 n, m\le 1000000 n , m ≤ 1 0 0 0 0 0 0
KMP 好题。我们考虑将判定相等转化一下,可以变为:在它之前比它小的数的个数。这个映射很容易证明是和原来的序列一一对应的。因此我们可以用这个条件来判定相等。我们先预处理出来 p p p c n t i cnt_i c n t i K M P KMP K M P
时间复杂度 O ( n log n ) O(n\log n) O ( n log n )
Fedya the Potter Strikes Back
给定一个字符串 S S S W W W n n n S S S c i c_i c i W W W w i w_i w i
定义一个子区间 [ L , R ] [L, R] [ L , R ] [ L , R ] [L,R] [ L , R ] [ 1 , R − L + 1 ] [1,R-L+1] [ 1 , R − L + 1 ] min i = L R W i \min_{i=L}^{R} W_i min i = L R W i 0 0 0
每次操作后,你都要求出当前的串的所有子区间的可疑度之和。
数据范围:1 ≤ n ≤ 6 × 1 0 5 1\leq n\leq 6\times 10 ^ 5 1 ≤ n ≤ 6 × 1 0 5 0 ≤ w i < 2 30 0\leq w_i < 2^{30} 0 ≤ w i < 2 3 0
我们考虑维护 Border 的集合。我们发现,新加入一个字符至多会在上一个的基础上增加一个 Border,因此我们直接删的复杂度是对的。
具体地说,我们维护一个 a n c i anc_i a n c i f a i l fail f a i l i i i i i i
至于权值的问题,我们发现小的值会覆盖掉大的值,因此我们使用单调栈,同时我们将大于 w i w_i w i w i w_i w i O ( log n ) O(\log n) O ( log n ) O ( n log n ) O(n\log n) O ( n log n )
字符串匹配
定义 A 1 = A A^1=A A 1 = A A n = A n − 1 A A^n = A^{n - 1} A A n = A n − 1 A n ≥ 2 n \ge 2 n ≥ 2 S = ( A B ) i C S = {(AB)}^iC S = ( A B ) i C F ( A ) ≤ F ( C ) F(A) \le F(C) F ( A ) ≤ F ( C ) F ( S ) F(S) F ( S ) S S S A A A B B B C C C
数据范围:∣ S ∣ ≤ 1 0 6 |S|\le 10^6 ∣ S ∣ ≤ 1 0 6
终于有 exkmp 可做的题了。
我们先不考虑 F ( A ) ≤ F ( C ) F(A) \le F(C) F ( A ) ≤ F ( C ) A A A B B B
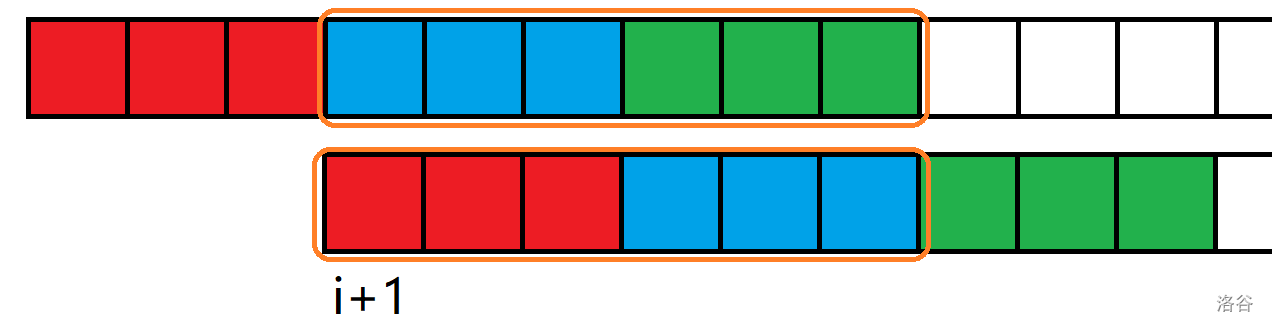
我们先把原字符串和原字符串的第 i + 1 i + 1 i + 1
我们可以清楚的看到相同颜色部分是相同的,框起来的部分也是相同的。手玩下就能得到当循环长度为 i i i ⌊ z [ i + 1 ] i ⌋ + 1 \left \lfloor \frac{z[i+1]}{i} \right \rfloor +1 ⌊ i z [ i + 1 ] ⌋ + 1
现在我们加上 F F F t t t t − ⌊ t 2 ⌋ t - \left \lfloor \frac{t}{2} \right \rfloor t − ⌊ 2 t ⌋ ⌊ t 2 ⌋ \left \lfloor \frac{t}{2} \right \rfloor ⌊ 2 t ⌋
当有奇数个循环时,我们考虑剩下的后缀的字母奇偶性都是等价的。因为我们加入两个循环时字符的奇偶性必然不会改变。因此我们维护单个变量 s u f i suf_i s u f i s [ i ∼ n ] s[i\sim n] s [ i ∼ n ] p r e i pre_i p r e i s [ 1 ∼ i ] s[1\sim i] s [ 1 ∼ i ] j j j p r e j ≤ s u f i pre_j\le suf_i p r e j ≤ s u f i i i i
而对于偶数个循环时同理,只不过 C C C p r e i pre_i p r e i j j j p r e j ≤ a l l pre_j\le all p r e j ≤ a l l
时间复杂度 O ( n log 26 ) O(n\log 26) O ( n log 2 6 )
Prefix-Suffix Palindrome
给定一个字符串。要求选取他的一个前缀(可以为空)和与该前缀不相交的一个后缀(可以为空)拼接成回文串,且该回文串长度最大。求该最大长度。
数据范围:∑ n ≤ 1 0 6 \sum n\leq 10^6 ∑ n ≤ 1 0 6
我们考虑如何拼接才是最大的。显然,我们先选取最长逆序相等的前后缀,然后再找一个和这个前后缀相交的回文串即可。如何求这个最长逆序相等的前后缀呢,我们可以把字符串反转后拼到原串后,跑一遍 exKMP,z n + 1 z_{n+1} z n + 1
最长双回文串
输入长度为 n n n S S S S S S T T T T T T X , Y X, Y X , Y ∣ X ∣ , ∣ Y ∣ ≥ 1 |X|,|Y|≥1 ∣ X ∣ , ∣ Y ∣ ≥ 1 X X X Y Y Y
数据范围:2 ≤ ∣ S ∣ ≤ 1 0 5 2\leq |S|\leq 10^5 2 ≤ ∣ S ∣ ≤ 1 0 5
我们先对原串跑一遍马拉车,求出每个点所对应的最长回文半径,然后从后往前递推出一个数组 m a x l i maxl_i m a x l i i i i
动物园
给定字符串 s s s n u m [ i ] num[i] n u m [ i ] s s s i i i ⌊ i 2 ⌋ \left \lfloor \frac{i}{2} \right \rfloor ⌊ 2 i ⌋ n u m [ i ] + 1 num[i]+1 n u m [ i ] + 1
数据范围:∣ s ∣ ≤ 1 0 6 |s|\le 10^6 ∣ s ∣ ≤ 1 0 6
我们考虑暴力:我们对于每个点暴力跳 n e x t next n e x t n u m num n u m
因为 border 的 border 也是 border,因此我们可以得到一个结论:n u m [ i ] = n u m [ j ] + 1 num[i]=num[j]+1 n u m [ i ] = n u m [ j ] + 1 j j j 1 ∼ i 1\sim i 1 ∼ i ⌊ i 2 ⌋ \left \lfloor \frac{i}{2} \right \rfloor ⌊ 2 i ⌋ ⌊ i 2 ⌋ \left \lfloor \frac{i}{2} \right \rfloor ⌊ 2 i ⌋ j j j ⌊ i 2 ⌋ \left \lfloor \frac{i}{2} \right \rfloor ⌊ 2 i ⌋ n e x t next n e x t
时间复杂度 O ( n ) O(n) O ( n )
优秀的拆分
如果一个字符串可以被拆分为 AABB \text{AABB} AABB A \text{A} A B \text{B} B n n n S S S
数据范围:n ≤ 30000 n\le 30000 n ≤ 3 0 0 0 0
我们考虑将 A A A B B B f i f_i f i i i i AA \text{AA} AA g i g_i g i i i i BB \text{BB} BB ∑ f i × g i + 1 \sum f_i\times g_{i+1} ∑ f i × g i + 1
我们考虑如何求出 f i f_i f i g i g_i g i A \text{A} A k k k AA \text{AA} AA
我们只需要考虑两个相邻检查点往前的 l c s lcs l c s l c p lcp l c p f f f 1 1 1
时间复杂度 O ( n log n ) O(n\log n) O ( n log n )
所有公共子序列问题
给定两个字符串 A , B A, B A , B A A A B B B
数据范围:∣ A ∣ , ∣ B ∣ ≤ 3000 |A|,|B|\le 3000 ∣ A ∣ , ∣ B ∣ ≤ 3 0 0 0
本题介绍一种新自动机:子序列自动机。具体的说,给定字符串 s s s n e [ i ] [ c ] ne[i][c] n e [ i ] [ c ] i i i c c c
它的用处主要有:统计字符串不同子序列个数、查询一个字符串是否是该字符串的子序列、两个字符串的公共子序列、因此本题说是子序列自动机的板子题也可以其实。
回到这题,我们可以同时对两个字符串在两个子序列自动机上走,每次枚举下一个字符填什么,然后走就完事了。统计答案也可以像在 DAG 上统计一样,DP 或者记忆化即可。
残缺的字符串
给定两个字符串 A , B A, B A , B *,表示这个位置可以为任意一个字符。求出对于 B B B i i i m m m A A A
数据范围:∣ A ∣ , ∣ B ∣ ≤ 3 × 1 0 5 |A|, |B| \le 3\times 10^5 ∣ A ∣ , ∣ B ∣ ≤ 3 × 1 0 5
这里介绍一个新东西:FFT 求字符串匹配。
先考虑没有通配符的情况,我们将每个位置附一个权值,那么两个字符串 a , b a, b a , b 1 1 1 ∑ i = 0 m − 1 ( a i − b i ) 2 \sum \limits_{i=0}^{m-1} (a_i-b_i)^2 i = 0 ∑ m − 1 ( a i − b i ) 2
而对于有通配符的情况,我们可以把通配符的权值设置为 0 0 0 ∑ i = 0 m − 1 ( a i − b i ) 2 a i b i \sum \limits_{i=0}^{m-1} (a_i-b_i)^2a_ib_i i = 0 ∑ m − 1 ( a i − b i ) 2 a i b i
∑ i = 0 m − 1 ( a i − b i + k ) 2 a i b i + k \sum \limits _{i=0}^{m-1}(a_i-b_{i+k})^2a_ib_{i+k}
i = 0 ∑ m − 1 ( a i − b i + k ) 2 a i b i + k
展开即为差卷积形式,NTT 即可。
时间复杂度 O ( n log n ) O(n\log n) O ( n log n )
歌唱王国
给定字符集大小 n n n m m m a a a b b b b b b b b b a a a
数据范围:n , ∣ a ∣ ≤ 1 0 7 n, |a|\le 10^7 n , ∣ a ∣ ≤ 1 0 7
我们用 PGF 来做这道题。
我们设 f i f_i f i i i i g i g_i g i i i i F ( x ) = ∑ f i x i \mathscr{F}(x)=\sum f_ix^i F ( x ) = ∑ f i x i G ( x ) = ∑ g i x i \mathscr{G}(x)=\sum g_ix^i G ( x ) = ∑ g i x i
通过观察可以发现 PGF 具有这两个性质:
F ( 1 ) = 1 \mathscr{F}(1)=1 F ( 1 ) = 1 1 1 1 F ′ ( 1 ) \mathscr{F}'(1) F ′ ( 1 ) i × f i i\times f_i i × f i E = ∑ i × f i E=\sum i\times f_i E = ∑ i × f i
我们再寻找 F ( x ) \mathscr{F}(x) F ( x ) G ( x ) \mathscr{G}(x) G ( x )
g i = f i + 1 + g i + 1 g_i=f_{i+1}+g_{i+1}
g i = f i + 1 + g i + 1
因为我们当前没有结束,那么下一轮有可能结束,也有可能不结束。我们对齐下标,可以得到:
x G ( x ) + 1 = F ( x ) + G ( x ) x\mathscr{G}(x)+1=\mathscr{F}(x)+\mathscr{G}(x)
x G ( x ) + 1 = F ( x ) + G ( x )
接下来这个性质比较难找。
我们设事件 A A A i i i m m m m m m a a a h i h_i h i
如果我们在一个还没结束的局面往后添加 m m m A A A h i = g i × 1 n m h_i=g_i\times \frac{1}{n^m} h i = g i × n m 1
当然,h i h_i h i i + y i+y i + y a a a 1 ≤ y ≤ m 1\le y\le m 1 ≤ y ≤ m a a a B i B_i B i P ( A ) = ∑ i = 1 n P ( A ∣ B i ) P ( B i ) P(A)=\sum_{i=1}^{n}P(A|B_i)P(B_i) P ( A ) = ∑ i = 1 n P ( A ∣ B i ) P ( B i )
h i = ∑ y = 1 m B y × 1 n m − y × [ y is border ] h_i=\sum_{y=1}^m B_y\times \frac{1}{n^{m-y}}\times [y \text{ is border}]
h i = y = 1 ∑ m B y × n m − y 1 × [ y is border ]
其中 [ y is border ] [y\text{ is border}] [ y is border ] a a a m m m a a a y y y a a a a a a a a a border \text{border} border
显然 B y = f i + y B_y=f_{i+y} B y = f i + y h i = ∑ y = 1 m f i + y × 1 n m − y × [ y is border ] h_i=\sum_{y=1}^m f_{i+y}\times \frac{1}{n^{m-y}}\times [y \text{ is border}] h i = ∑ y = 1 m f i + y × n m − y 1 × [ y is border ]
我们用两种方式写出了 h i h_i h i
g i × 1 n m = ∑ y = 1 m f i + y × 1 n m − y × [ y is border ] g_i\times \frac{1}{n^m}=\sum_{y=1}^m f_{i+y}\times \frac{1}{n^{m-y}}\times [y \text{ is border}]
g i × n m 1 = y = 1 ∑ m f i + y × n m − y 1 × [ y is border ]
两边同时乘上 n m n^m n m
g i = ∑ y = 1 m f i + y × n y × [ y is border ] g_i=\sum_{y=1}^mf_{i+y}\times n^y\times [y\text{ is border}]
g i = y = 1 ∑ m f i + y × n y × [ y is border ]
我们为了对齐,给 G ( x ) \mathscr{G}(x) G ( x ) x m x^m x m i i i g i + m g_{i+m} g i + m F ( x ) \mathscr{F}(x) F ( x ) x m − y x^{m-y} x m − y i i i i + y + m − y = i + m i+y+m-y=i+m i + y + m − y = i + m
x m G ( x ) = ∑ y = 1 m F ( x ) × n y × [ y is border ] x^m\mathscr{G}(x)=\sum_{y=1}^m\mathscr{F}(x)\times n^{y}\times [y\text{ is border}]
x m G ( x ) = y = 1 ∑ m F ( x ) × n y × [ y is border ]
我们有了这两个式子后,我们进行一些推导:
x G ( x ) + 1 = F ( x ) + G ( x ) ( x − 1 ) G ( x ) + 1 = F ( x ) \begin{aligned}
x\mathscr{G}(x)+1&=\mathscr{F}(x)+\mathscr{G}(x)\\
(x-1)\mathscr{G}(x)+1&=\mathscr{F}(x)
\end{aligned}
x G ( x ) + 1 ( x − 1 ) G ( x ) + 1 = F ( x ) + G ( x ) = F ( x )
两边求导得到:
F ′ ( x ) = G ( x ) + ( x − 1 ) G ′ ( x ) \begin{aligned}
\mathscr{F}'(x)=\mathscr{G}(x)+(x-1)\mathscr{G}'(x)
\end{aligned}
F ′ ( x ) = G ( x ) + ( x − 1 ) G ′ ( x )
带入 x = 1 x=1 x = 1 F ′ ( 1 ) = G ( 1 ) \mathscr{F}'(1)=\mathscr{G}(1) F ′ ( 1 ) = G ( 1 ) G ( 1 ) \mathscr{G}(1) G ( 1 )
我们再将 x = 1 x=1 x = 1 x m G ( x ) = ∑ y = 1 m F ( x ) × n y × [ y is border ] x^m\mathscr{G}(x)=\sum_{y=1}^m\mathscr{F}(x)\times n^{y}\times [y\text{ is border}] x m G ( x ) = ∑ y = 1 m F ( x ) × n y × [ y is border ]
G ( 1 ) = ∑ y = 1 m F ( 1 ) × n y × [ y is border ] \mathscr{G}(1)=\sum_{y=1}^m\mathscr{F}(1)\times n^y\times [y \text{ is border}]
G ( 1 ) = y = 1 ∑ m F ( 1 ) × n y × [ y is border ]
由于 F ( 1 ) = 1 \mathscr{F}(1)=1 F ( 1 ) = 1
G ( 1 ) = ∑ y = 1 m n y × [ y is border ] \mathscr{G}(1)=\sum_{y=1}^mn^y\times [y \text{ is border}]
G ( 1 ) = y = 1 ∑ m n y × [ y is border ]
我们直接跳 border \text{border} border O ( n ) O(n) O ( n )
Kefa and Watch
给定长度为 n n n 0 ∼ 9 0\sim 9 0 ∼ 9 d d d
数据范围:n ≤ 1 0 5 n\le 10^5 n ≤ 1 0 5
根据周期的定义,周期就等于长度减去它的 border 长度。因此我们只需要判断是否存在长度为 l e n − d len-d l e n − d
时间复杂度 O ( n log n ) O(n\log n) O ( n log n )
Yet Another LCP Problem
记 l c p ( i , j ) lcp(i,j) l c p ( i , j ) A A A B B B ∑ i ∈ A , j ∈ B l c p ( i , j ) \sum_{i \in A,j \in B}lcp(i,j) ∑ i ∈ A , j ∈ B l c p ( i , j )
数据范围:n ≤ 2 × 1 0 5 , ∑ ∣ A ∣ + ∣ B ∣ ≤ 2 × 1 0 5 n\le 2\times 10^5, \sum |A|+|B| \le 2\times 10^5 n ≤ 2 × 1 0 5 , ∑ ∣ A ∣ + ∣ B ∣ ≤ 2 × 1 0 5
我们先把字符串翻转,将 l c p lcp l c p l c s lcs l c s [AHOI2013]差异 的套路,我们建出来 SAM,这样两个点在 parent tree 上对应的 lca 的 l e n len l e n
但是这里有多组询问,我们就可以每组询问建虚树,然后在虚树上进行 dp 计算答案。具体的说,我们设 s u m u , 0 sum_{u, 0} s u m u , 0 u u u A A A s u m u , 1 sum_{u, 1} s u m u , 1 u u u B B B a ∈ A , b ∈ B a\in A, b\in B a ∈ A , b ∈ B u u u l e n u len_u l e n u
时间复杂度 O ( n log n ) O(n\log n) O ( n log n )
Check Transcription
给定一个 01 01 0 1 t t t s s s ( r 0 , r 1 ) (r_0, r_1) ( r 0 , r 1 ) r 0 ≠ r 1 r_0 \neq r_1 r 0 = r 1 t t t 0 0 0 r 0 r_0 r 0 1 1 1 r 1 r_1 r 1 s s s
数据范围:2 ≤ ∣ t ∣ ≤ 1 0 5 2 \leq |t| \leq 10^5 2 ≤ ∣ t ∣ ≤ 1 0 5 1 ≤ ∣ s ∣ ≤ 1 0 6 1 \leq |s| \leq 10^6 1 ≤ ∣ s ∣ ≤ 1 0 6
我们直接枚举第一位 0/1 的长度,这样我们就能得到它的哈希值,同时我们也能算出另一种字符串的长度(我们假设第一位为 0 0 0 01 01 0 1
复杂度证明:
我们先设 s 1 s_1 s 1 s 2 s_2 s 2 c n t 0 cnt_0 c n t 0 c n t 1 cnt_1 c n t 1
我们一共会枚举 ∣ s 1 ∣ c n t 0 \frac{|s1|}{cnt_0} c n t 0 ∣ s 1 ∣ l e n len l e n c n t 0 cnt_0 c n t 0 c n t 1 cnt_1 c n t 1
c n t 0 × l e n 0 + c n t 1 × l e n 1 = ∣ s 1 ∣ cnt_0\times len_0 + cnt_1\times len_1=|s_1|
c n t 0 × l e n 0 + c n t 1 × l e n 1 = ∣ s 1 ∣
根据 exgcd,我们可以得到 l e n 0 len_0 l e n 0 c n t 1 gcd ( c n t 0 , c n t 1 ) \frac{cnt_1}{\gcd(cnt_0, cnt_1)} g c d ( c n t 0 , c n t 1 ) c n t 1 ∣ s 1 ∣ × gcd ( c n t 0 , c n t 1 ) c n t 0 × c n t 1 \frac{|s_1|\times \gcd(cnt_0, cnt_1)}{cnt_0\times cnt_1} c n t 0 × c n t 1 ∣ s 1 ∣ × g c d ( c n t 0 , c n t 1 ) O ( ∣ s 2 ∣ ) O(|s_2|) O ( ∣ s 2 ∣ )
∣ s 2 ∣ × ∣ s 1 ∣ × gcd ( c n t 0 , c n t 1 ) c n t 0 × c n t 1 \frac{|s_2|\times |s_1|\times \gcd(cnt_0, cnt_1)}{cnt_0\times cnt_1}
c n t 0 × c n t 1 ∣ s 2 ∣ × ∣ s 1 ∣ × g cd( c n t 0 , c n t 1 )
我们让所有 c n t 0 cnt_0 c n t 0 O ( ∣ s 1 ∣ ) O(|s_1|) O ( ∣ s 1 ∣ )
Two Permutations
给出两个排列 a , b a,b a , b n , m n,m n , m x x x a 1 + x , a 2 + x , . . . a n + x a_1 + x,a_2 + x,...a_n + x a 1 + x , a 2 + x , . . . a n + x b b b
数据范围:n ≤ m ≤ 2 × 1 0 5 n \leq m \leq 2 \times 10^5 n ≤ m ≤ 2 × 1 0 5
我们枚举 x x x b b b b b b a a a x x x a a a
时间复杂度 O ( n log n ) O(n\log n) O ( n log n )
e-Government
维护一个字符串集合,支持三种操作:
加字符串
删字符串
查询集合中的所有字符串在给出的模板串中出现的次数
数据范围:m ≤ 3 × 1 0 5 , ∑ ∣ s i ∣ ≤ 3 × 1 0 5 m \leq 3 \times 10^5, \sum |s_i| \leq 3\times 10^5 m ≤ 3 × 1 0 5 , ∑ ∣ s i ∣ ≤ 3 × 1 0 5
我们先考虑没有删除加入时如何做。我们先把所有字符串加进 Trie 里面,在建 AC 自动机的时候按照 fail 向下更新出现次数即可。而在跑匹配的时候我们只需要把经过的点的权值加入即可。
而对应添加和删除操作,我们思考下更新的本质。一个点的贡献会沿着它在 fail 树上的边向下一直传下去,而我们要消除这些贡献或者增加这些贡献,只需要将它在 fail 树中的子树全部减去它的贡献即可。因此我们再把 fail 树建出来,每次添加删除直接子树 + 1 +1 + 1 − 1 -1 − 1
时间复杂度 O ( ∑ ∣ s i ∣ log n + ∣ T ∣ ) O(\sum |s_i|\log n + |T|) O ( ∑ ∣ s i ∣ log n + ∣ T ∣ )
String Set Queries
维护一个字符串集合,支持三种操作,强制在线 :
加字符串
删字符串
查询集合中的所有字符串在给出的模板串中出现的次数
数据范围:m ≤ 3 × 1 0 5 , ∑ ∣ s i ∣ ≤ 3 × 1 0 5 m \leq 3 \times 10^5, \sum |s_i| \leq 3\times 10^5 m ≤ 3 × 1 0 5 , ∑ ∣ s i ∣ ≤ 3 × 1 0 5
本题和上面的区别就是强制在线。
做法 1:
二进制分组。我们对每次插入的一个字符串建立一个 AC 自动机,而当两个 AC 自动机大小相等时我们把这两个 AC 自动机暴力合并重构。每次查询就在 log n \log n log n
时间复杂度 O ( n log n ) O(n\log n) O ( n log n )
做法 2:
我们直接哈希。每次直接枚举字符串 t t t ∣ s i ∣ |s_i| ∣ s i ∣
时间复杂度 O ( n n ) O(n\sqrt n) O ( n n ) 1 2 3 4 ...。这样最多会有 n \sqrt n n n n n\sqrt n n n
做法 3:
我们考虑根号分治。我们对于长度大于 n \sqrt n n s i s_i s i n \sqrt n n t i t_i t i n \sqrt n n n \sqrt n n O ( n n ) O(n\sqrt n) O ( n n )
[NOI2018] 你的名字
给定一个字符串 S S S T T T T T T S [ l ∼ r ] S[l\sim r] S [ l ∼ r ]
数据范围:∣ S ∣ ≤ 5 × 1 0 5 , ∑ ∣ T ∣ ≤ 1 0 6 |S|\le 5\times 10^5, \sum |T|\le 10^6 ∣ S ∣ ≤ 5 × 1 0 5 , ∑ ∣ T ∣ ≤ 1 0 6
我们先考虑 L = 1 , R = ∣ S ∣ L=1, R = |S| L = 1 , R = ∣ S ∣ S S S T T T T T T i i i S S S T T T i i i l i n k link l i n k
最后我们将每一个前缀的满足上面要求的最长后缀记录为 l i m i lim_i l i m i i i i t a g i tag_i t a g i
∑ p = 1 i d x max ( 0 , l e n ( p ) − max ( l e n ( l i n k ( p ) ) , l i m t a g p ) ) \sum \limits_{p=1}^{idx}\max(0, \mathrm{len}(p)-\max(\mathrm{len}(\mathrm{link}(p)), lim_{tag_p}))
p = 1 ∑ i d x max ( 0 , l e n ( p ) − max ( l e n ( l i n k ( p ) ) , l i m t a g p ) )
也就是对于每个节点,我们用它的长度减去它匹配的长度就是它不为 S S S
而对于有了区间限制这个东西,我们可以思考一下我们上面用 SAM 都做了什么:跳 l i n k link l i n k e n d p o s \mathrm{endpos} e n d p o s
而对于 e n d p o s \mathrm{endpos} e n d p o s
时间复杂度 O ( n log n ) O(n\log n) O ( n log n )
区间本质不同子串个数
给定一个长度为 n n n S S S m m m S S S L L L R R R
数据范围:n ≤ 1 0 5 , m ≤ 2 × 1 0 5 n\le 10^5, m\le 2\times 10^5 n ≤ 1 0 5 , m ≤ 2 × 1 0 5
对于区间数不同颜色这种问题,一个常见的套路为讲询问离线,然后右端点扫描线,同时只维护每个不同元素在最右端出现的位置。
而对于这题我们也可以这么做。我们把询问离线后做扫描线,发现每次新加入的元素的 e n d p o s \mathrm{endpos} e n d p o s
我们就可以沿用[SDOI2017] 树点涂色 的套路,用 LCT 来维护这个过程。具体地说,我们在 LCT 的每个点维护一个 v a l val v a l e n d p o s \mathrm{endpos} e n d p o s v a l val v a l
时间复杂度 O ( n log 2 n ) O(n\log^2n) O ( n log 2 n )
Luogu 5287
给定一个初始为空的字符串,支持两种操作:
在串末尾添加 x x x c c c
回溯到第 x x x
每次操作完后输出 ∑ i = 1 ∣ s ∣ n e x t i \sum_{i=1}^{|s|}next_i ∑ i = 1 ∣ s ∣ n e x t i n e x t i next_i n e x t i n e x t next n e x t
数据范围:n ≤ 1 0 5 , x ≤ 1 0 4 n\le 10^5, x\le 10^4 n ≤ 1 0 5 , x ≤ 1 0 4
回溯操作其实可以离线在操作树上 dfs 一遍。现在只需要考虑往后添加字符的操作。如果把最终匹配的末尾那一段掐头去尾,可以发现中间那些段的字符以及长度都是相同的,这启示我们可以把 ( x , c ) (x, c) ( x , c )
暴力的做法就是每次加入字符后类似 kmp 那样暴力跳,但是这样复杂度是均摊的,不支持回溯,需要一种不均摊复杂度的东西。可以使用 kmp 自动机,设 f i , x , c f_{i, x, c} f i , x , c i i i ( x , c ) (x, c) ( x , c )
加入的贡献就是匹配长度以及一串等差数列,依旧在主席树上维护即可。
时间复杂度 O ( n log n ) O(n\log n) O ( n log n )
Luogu 3546
对于两个串 S 1 , S 2 S_1, S_2 S 1 , S 2 S 1 S_1 S 1 S 2 S_2 S 2 S 1 S_1 S 1 S 2 S_2 S 2
给出一个长度为 n n n S S S L ( L ≤ n 2 ) L(L\leq \frac n 2) L ( L ≤ 2 n ) S S S L L L S S S L L L
数据范围:n ≤ 1 0 6 n\le 10^6 n ≤ 1 0 6
显然这样的前后缀是形如 A B ⋯ B A AB\cdots BA A B ⋯ B A A A A
注意到要求的区间 border 是以整个字符串为中心的,每次在两边添加一个字母。画图可以发现,对于一个长度为 i i i t t t s s s border ( s ) ≤ border ( t ) + 2 \text{border}(s)\le \text{border}(t)+2 border ( s ) ≤ border ( t ) + 2
具体证明可以从 s s s s s s border \text{border} border t t t border \text{border} border
再用字符串哈希判断是否为 border \text{border} border
时间复杂度 O ( n ) O(n) O ( n )
Luogu 7361
给定字符串 s s s l , r l, r l , r [ l , r ] [l, r] [ l , r ]
数据范围:n ≤ 5 × 1 0 4 , q ≤ 1 0 5 n\le 5\times 10^4, q\le 10^5 n ≤ 5 × 1 0 4 , q ≤ 1 0 5
建出来 SAM,用很经典的套路:线段树合并维护 edp \text{edp} edp l e n len l e n edp \text{edp} edp [ l + l e n − 1 , r ] [l+len-1, r] [ l + l e n − 1 , r ] edp \text{edp} edp
现在一个点所代表的字符串长度是一段区间 [ len link ( u ) , len u ] [\text{len}_{\text{link}(u)}, \text{len}_u] [ len link ( u ) , len u ] edp \text{edp} edp ( l , r ) (l, r) ( l , r ) [ 1 , l − len ( u ) ] [1, l-\text{len}(u)] [ 1 , l − len ( u ) ] [ r , n ] [r, n] [ r , n ] len u \text{len}_u len u [ l − len u + 1 , l ] [l - \text{len}_u+1, l] [ l − len u + 1 , l ] [ r , n ] [r, n] [ r , n ] x x x l + 1 − x l+1-x l + 1 − x
直接进行李超树,扫描线即可。
时间复杂度 O ( n log 3 n + q log n ) O(n\log^3 n+q\log n) O ( n log 3 n + q log n )
CF1063F
对于一个字符串数组 t 1 , … , t k t_1, \ldots, t_k t 1 , … , t k t i t_i t i t i − 1 t_{i-1} t i − 1 t i t_i t i t i − 1 t_{i - 1} t i − 1 t i ≠ t i − 1 t_i \ne t_{i-1} t i = t i − 1
给定字符串 s s s t 1 , … , t k t_1,\ldots,t_k t 1 , … , t k u 1 , … , u k + 1 u_1,\ldots,u_{k+1} u 1 , … , u k + 1 s = u 1 + t 1 + u 2 + t 2 + ⋯ + t k + u k + 1 s=u_1+t_1+u_2+t_2 + \cdots +t_k+u_{k+1} s = u 1 + t 1 + u 2 + t 2 + ⋯ + t k + u k + 1 + + +
现在给定一个字符串,求满足条件的最大 k k k
数据范围:∣ s ∣ ≤ 5 × 1 0 5 |s|\le 5\times 10^5 ∣ s ∣ ≤ 5 × 1 0 5
哈希 O ( n n ) O(n\sqrt n) O ( n n )
显然 ∣ t i ∣ = i |t_i|=i ∣ t i ∣ = i f i f_i f i i i i f i − 1 ≤ f i + 1 f_i-1\le f_{i+1} f i − 1 ≤ f i + 1 i i i i + 1 i+1 i + 1 f i − 1 f_i-1 f i − 1
移项可得 f i ≤ f i + 1 + 1 f_i\le f_{i+1}+1 f i ≤ f i + 1 + 1 f i = f i + 1 + 1 f_i=f_{i+1}+1 f i = f i + 1 + 1 O ( n ) O(n) O ( n )
目前问题就是如何判断是否合法,分析合法条件为:
存在一个 j > i + f i − 1 j>i+f_i-1 j > i + f i − 1 s [ j , j + f i − 2 ] s[j, j+f_i-2] s [ j , j + f i − 2 ] s [ i , i + f i − 1 ] s[i,i+f_i-1] s [ i , i + f i − 1 ] f j ≥ f i − 1 f_j\ge f_i-1 f j ≥ f i − 1
分析子串这个条件,就可以发现只有两种可能:
s [ i , i + f i − 2 ] s[i,i+f_i-2] s [ i , i + f i − 2 ] suf ( j ) \text{suf}(j) suf ( j ) s [ i + 1 , i + f i − 1 ] s[i+1,i+f_i-1] s [ i + 1 , i + f i − 1 ] suf ( j ) \text{suf}(j) suf ( j )
前缀这个条件可以转化为后缀树上的祖先后代关系。具体的说,如果在后缀树上 u u u v v v u u u v v v
问题转化为:在后缀树上查询子树内是否存在一个二元组 ( f j , j ) (f_j, j) ( f j , j ) f j > f i − 1 f_j>f_i-1 f j > f i − 1 j > i + f i − 1 j>i+f_i-1 j > i + f i − 1
由于每次要么 f i f_i f i i i i f i f_i f i i + f i i+f_i i + f i j > i + f i − 1 j>i+f_i-1 j > i + f i − 1
时间复杂度 O ( n log n ) O(n\log n) O ( n log n )